
Under Review
LiME: Lightweight Mixture
of Experts
Expert specialization through lightweight modulation vectors and zero-parameter routing for efficient multimodal multi-task learning
Expert specialization through lightweight modulation vectors and zero-parameter routing for efficient multimodal multi-task learning
LiME replaces heavy per-expert parameters with lightweight modulation vectors and a zero-parameter router — enabling efficient expert specialization at a fraction of the cost.
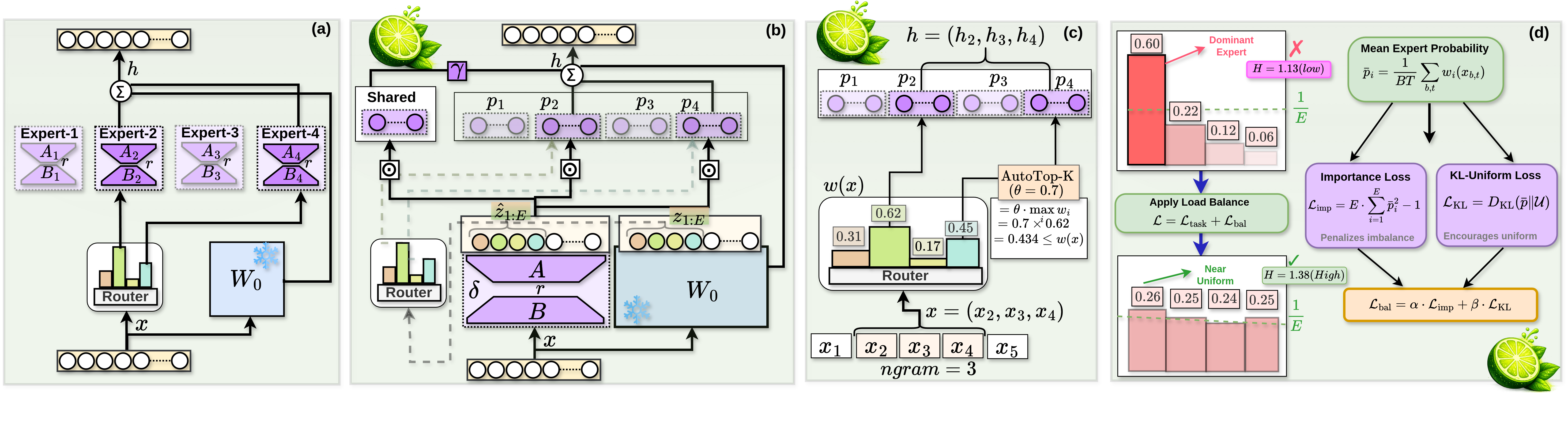
Figure 1. LiME architecture — (a) Standard MoE-LoRA, (b) LiME shared adapter + modulation, (c) AutoTop-K routing, (d) Load balancing losses.
A single shared LoRA adapter modulated by lightweight per-expert vectors — dramatically reducing parameters while preserving specialization.
Expert routing via n-gram hidden-state similarity — no learned gating weights, no auxiliary parameters, no routing collapse.
Dynamically adjusts expert activation per token based on confidence thresholds, enabling adaptive computation.
Importance loss + KL-uniform loss ensures experts are utilized evenly, preventing dominant-expert collapse.
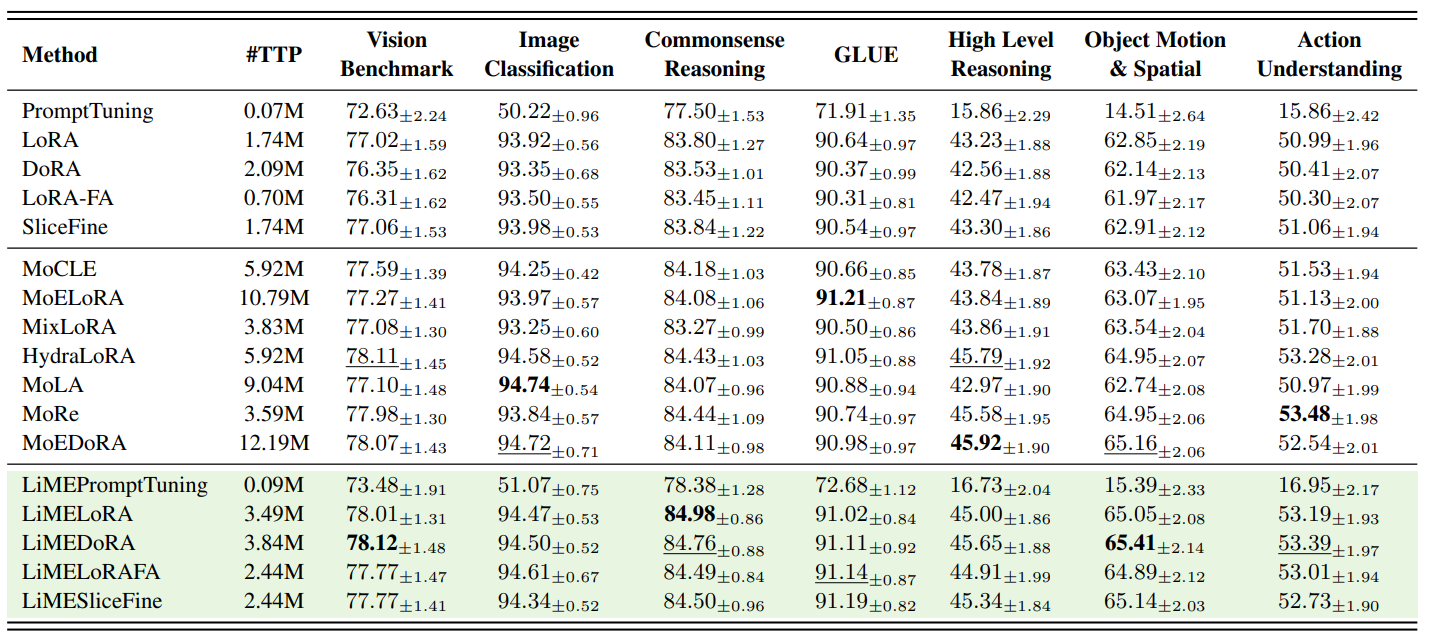
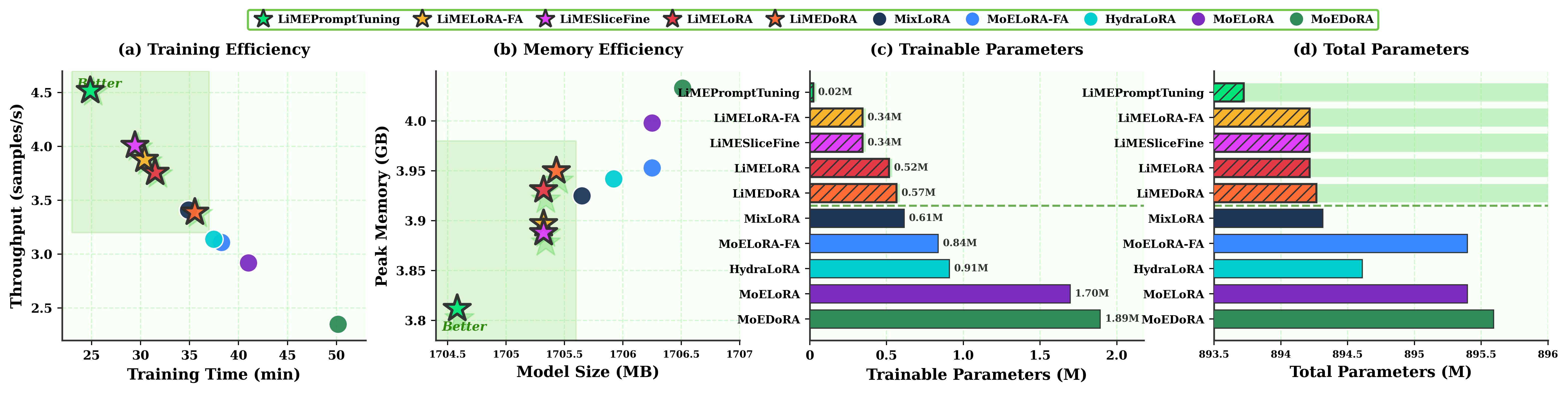
LiME matches or outperforms existing MoE-PEFT methods with up to 4× fewer trainable parameters and higher throughput.
Apply LiME to any pretrained model with just a few lines of code. Compatible with LLaVA-OneVision, Qwen2-VL, and more.
Clone the repository and install required packages.
Wrap any model with LiME using a single function call.
Use our custom trainer with specialized learning rates for MoE and PEFT components.
from LiMELoRA import apply_peft from transformers import LlavaOnevisionForConditionalGeneration # Load your base model model = LlavaOnevisionForConditionalGeneration.from_pretrained( "llava-onevision-qwen2-7b-ov-hf", torch_dtype=torch.bfloat16, device_map="auto", ) # ⭐ Apply LiME — one line is all you need model = apply_peft( model, targets=["q_proj", "k_proj", "v_proj", "o_proj", "out_proj"], num_experts=4, rank=2, use_shared_LiME=True, n_gram=1, top_k=1, rep_mode="token", jitter_noise=0.1, tokenizer=processor.tokenizer, temperature=0.5, gamma_routing=0.7, auto_topk=True, auto_topk_threshold=0.5, )
from trainer import LiMEArguments, LiMETrainer training_args = LiMEArguments( output_dir="./llava-lime-finetuned", per_device_train_batch_size=5, gradient_accumulation_steps=4, num_train_epochs=4, bf16=True, learning_rate=2e-4, moe_lr=1e-3, # Dedicated LR for routing components peft_lr=4e-4, # Dedicated LR for LoRA A/B importance_coef=0.1, kl_coef=0.01, balance_every_n_steps=50, ) trainer = LiMETrainer( model=model, args=training_args, train_dataset=train_dataset, tokenizer=processor.tokenizer, data_collator=collator, ) trainer.train()
A comprehensive multimodal multi-task benchmark with 47 tasks spanning vision, language, reasoning, and video understanding.
# Download the HuggingFace dataset pip install datasets python -c "from datasets import load_dataset; load_dataset('Kowsher/MMT-47')" # Download images huggingface-cli download \ Kowsher/MMT-47 \ --repo-type dataset \ --include "images/*" \ --local-dir images/ # Extract images (images.zip is a zip file) cd images && unzip images.zip && cd ..
# Download video data from MVTamperBench huggingface-cli download \ Srikant86/MVTamperBench \ --repo-type dataset \ --include "video/*" \ --local-dir videos/ # Extract all video zip files cd videos/ for f in *.zip; do d="${f%.zip}" if [ -d "$d" ]; then echo "Skipping $f (already extracted)" else echo "Extracting $f" unzip "$f" -d "$d" fi done cd ..
If you find LiME useful in your research, please consider citing our paper.